Workflow Automation Program Rescue: A Step-by-Step Guide

A workflow automation program that has stalled is rescued by triage, not by a restart. The instinct to scrap it and begin again is usually wrong, because the problem is rarely the effort or the tooling; it is almost always architecture, ownership, or governance that was never set. The sequence that works is to assess what is actually broken, stabilize the parts that are bleeding, fix the foundation before adding anything new, and only then resume building. i3solutions has taken stalled automation efforts and turned them into programs that pay for themselves, including one for a nuclear operator that returned its full investment within three months.
A stalled automation program looks the same across very different organizations. There are a handful of flows in production, some half-finished, a backlog nobody trusts, and a growing sense that the platform was oversold. People have stopped asking for new automations because the last few were late or broke. The temptation at this point is to declare the program a failure and start over with a new tool or a new vendor. That is almost always the expensive wrong move, because starting over throws away the working flows along with the broken ones and repeats the mistake that caused the stall, which was never the tool.
A rescue is triage. You stabilize before you optimize, and you diagnose before you build. The sequence has four steps and the order is the whole point.
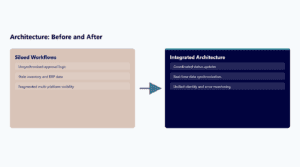
Assess what is actually broken. Before touching anything, inventory what exists: which flows run, which fail, who owns them, and where the business logic lives. In most stalled programs the root cause is not coding effort; it is structural. No one owns the platform, so standards drifted. Flows were built point to point with no shared architecture, so each one is fragile. There is no governance, so makers built whatever they wanted and now nothing is maintainable. Name the real cause before you spend a dollar fixing symptoms, because fixing symptoms is how the program stalled in the first place.
Stabilize what is bleeding. Some failures are costing you right now: a broken flow in a compliance-relevant process, an automation everyone depends on that fails intermittently. Fix those first to stop the active damage and to buy credibility back, because a rescue with no early visible win loses the room. This is field dressing, not reconstruction, and it is deliberately narrow.
Fix the foundation. This is the step that distinguishes a rescue from a patch. Establish ownership of the platform, set the governance and the standards that were missing, and rework the architecture so flows share a foundation instead of each being a one-off. This is unglamorous and it is where the durable value is, because it is what stops the next stall. Skipping it gives you a program that works for a quarter and then drifts again.
Resume building, now on solid ground. Only after the foundation is set do you go back to the backlog, and now new automation is fast and safe because it is built on governed, owned, shared infrastructure rather than added to a pile.
Sometimes the honest answer is harder than a rescue. If the platform genuinely cannot do what the business needs, or if the original work is so thin there is nothing worth keeping, a deliberate restart is the right call. But that is a finding you reach after the assessment, not a default you choose to avoid the diagnosis. The far more common truth is that the work is salvageable and the program stalled for want of ownership and architecture, which are fixable.
What the payoff looks like is worth stating plainly. For a nuclear power operator, i3 took an automation effort that was not delivering and turned it into a working program that saved about $293,000 a year and returned its full cost within three months. That return did not come from heroic coding. It came from diagnosing the real problem, fixing the foundation, and then letting the automation do what it was supposed to do all along. A stalled program is usually a lot closer to that outcome than it feels from inside the stall.
Key Takeaways
- Rescue a stalled automation program with triage, not a restart; the cause is usually architecture, ownership, or governance, not effort or tooling.
- Step one is assessment: inventory what runs, what fails, who owns it, and name the real root cause before spending.
- Step two is stabilizing the actively bleeding failures, to stop damage and earn back credibility with an early win.
- Step three, the one that distinguishes a rescue from a patch, is fixing the foundation: ownership, governance, shared architecture.
- A full restart is sometimes right, but only as a finding after assessment. (One rescued program returned its full cost in three months.)
Frequently Asked Questions
Should we scrap a stalled automation program and start over?
Usually not. Starting over discards the working flows with the broken ones and repeats the original mistake, which was rarely the tool. Assess first; a restart is a finding you reach after diagnosis, not a default.
Why do automation programs stall?
Most often for structural reasons: no one owns the platform, flows were built point to point with no shared architecture, and there was no governance, so the work became unmaintainable. The coding effort is rarely the root cause.
What is the first step in a rescue?
An assessment. Inventory which flows run, which fail, who owns them, and where the logic lives, then name the real root cause before spending on fixes.
How fast can a rescue pay off?
It varies, but the value comes from fixing the foundation, not from more coding. One rescued program for a nuclear operator saved about $293K a year and returned its full cost within three months.
What does fixing the foundation mean?
Establishing platform ownership, setting the missing governance and standards, and reworking the architecture so flows share a foundation. This is the step that prevents the next stall.
If your automation program has stalled, the first thing worth doing is an honest assessment of what is actually broken, because the answer is usually more fixable than it feels from the inside. Bring us what you have built so far and we will tell you plainly what is salvageable, what the real root cause is, and what a rescue would take, including the rare case where a deliberate restart is the right call.
About the Author
Michael Branson, Founder and COO, i3solutions. LinkedIn